Hi,
I’m implementing a 3-stage packet classification on Tofino:
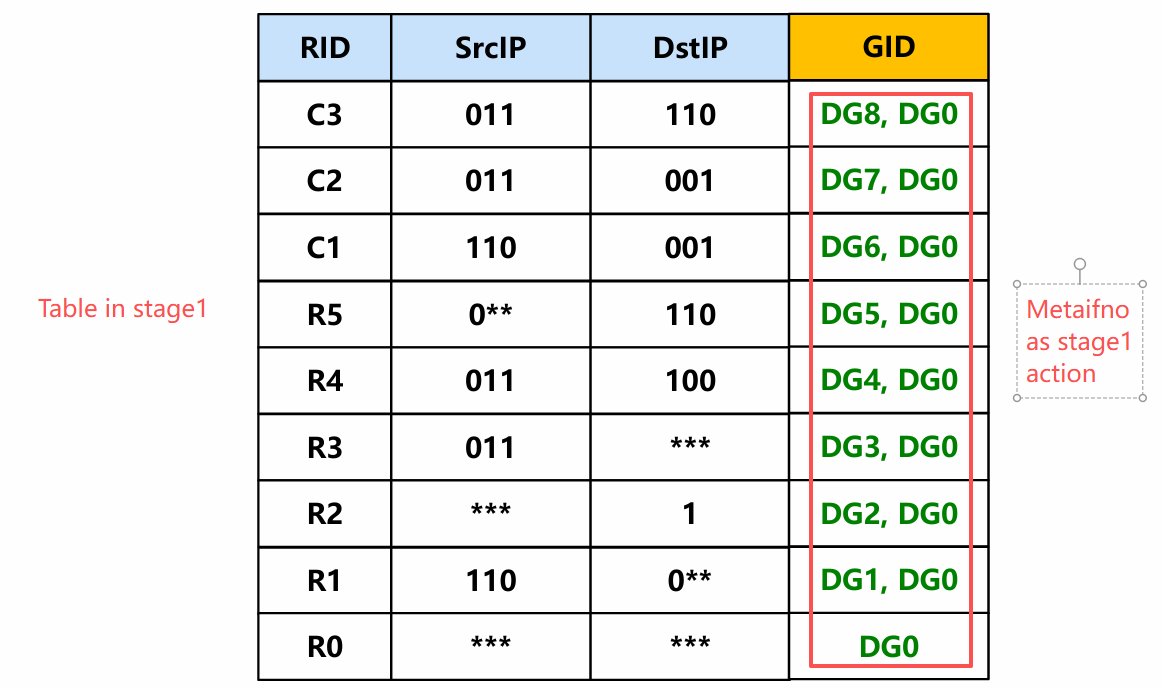
Stage-1: IP/Proto TCAM → outputs two metaifno (primary, secondary).
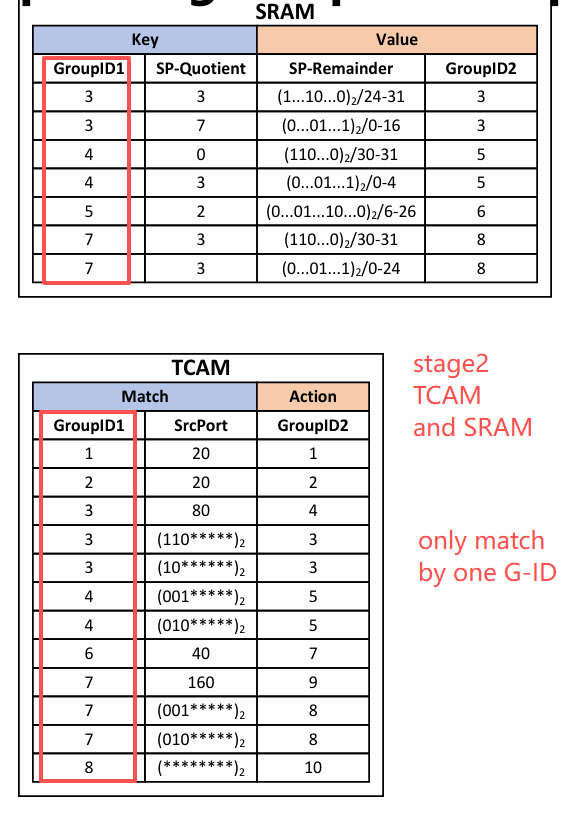
Stage-2: SRC port matching — use metaifno to lookup either TCAM or SRAM.
Requirement: if Stage-2 lookup using metaifno_primary fails, we should fallback and try metaifno_secondary. Hardware/compiler constraints:
P4 (Tofino) forbids multiple non-mutually-exclusive table.apply() on same table instance.
Dynamic bit-shifts / runtime 1 << remainder in P4 are not allowed on the target — so bitmap checks are performed by control-plane expansion (control-plane generates exact entries per bitmap bit).
What I tried:
- Control-plane duplication — for every rule I install identical entries under both GID_primary and GID_secondary. Works logically but doubles table entries.
- Data-plane fallback — create src_tcam_table/src_sram_table for primary and src_tcam_table_secondary/src_sram_table_secondary for secondary, then check primary tables then secondary tables. Works, but needs extra tables
Questions:
- Are there common P4 patterns / idioms to implement a fallback over two group IDs without doubling table entries and without multiple apply calls on same table?
- Is it acceptable/normal to duplicate table keys in the control plane in production (memory vs correctness tradeoff)? Any suggestions to reduce footprint?
- Can action selectors / indirect resources (action profiles) be used to express fallback semantics efficiently?
- Any Tofino-specific recommendations for implementing a prioritized fallback metaifno lookup?
Complete ACL matching flow in my data plane
if (table1.apply().hit) {
// Calculate port quotient for SRAM lookup
ig_md.src_quotient = p.udp.sport[15:5]; // High 11 bits
ig_md.dst_quotient = p.udp.dport[15:5];
// Stage-2
bool tcam1_match = tcam_table1.apply().hit;
bool sram1_match = sram_table1.apply().hit;
bool stage2_match_primary = tcam1_match || sram1_match;
// Try secondary metainfo tables if primary fails
bool src_match2 = false;
if (!stage2_match_primary && ig_md.metainfo_secondary != 511) {
bool tcam2_match = tcam2_table_secondary.apply().hit;
bool sram2_match = sram2_table_secondary.apply().hit;
if (tcam_match_sec || sram_match_sec) {
stage2_match_secondary = true;
}
}
bool stage2_match = stage2_match_primary || stage2_match_secondary;
...
}
} else {
drop();
Thanks in advance for pointers or pointers to existing designs.